利用MATLAB進行電腦視覺深度學習
機器學習技術在近幾十年間被電腦視覺工程師廣泛地利用來偵測影像中的物件,並對物件進行分類或辨識。工程師們擷取一些代表了點、區域、或感興趣物件的特徵,接著利用這些特徵來訓練一個可以進行分類或讓機器在影像資料中自行學習模式的模型。
傳統機器學習的做法,特徵選取(feature selection)是一項仰賴人工且耗時的過程,先找出感興趣的點或區域之後,再進行特徵擷取(feature extraction)。特徵擷取通常包含對每一張影像進行一或多種的影像處理操作,像是計算梯度來從每一張影像擷取出具有鑑別度的資料。
接著來談深度學習。深度學習演算法可以直接從影像、文字、與聲音中進行特徵、表現、以及任務的學習,來降低以人工進行特徵選取的需求。
本篇文章將以簡單的物件偵測與辨識範例,輕鬆地利用MATLAB®工具來進行深度學習,在無需具備豐富先進的電腦視覺演算法或類神經網路相關知識的條件下即可進行。
下載範例中使用的程式碼開始操作
這個範例的目標是要訓練出一個能從影片中偵測出一隻寵物的演算法,並且正確地將該寵物標記為貓或狗。我們使用的是卷積神經網路( convolutional neural network,CNN),它是一個特定的深度學習演算法類型,可以執行分類及從原始圖片擷取特徵。
在MATLAB中,只要具備一個預先已訓練過(pretrained)的CNN和幾張狗跟貓的圖片,就可已建立物件偵測與辨識演算法。我們利用CNN從影像中擷取出具有鑑別性的特徵,接著利用MATLAB app來訓練一個機器學習演算法以區分貓和狗。
匯入一個CNN分類器
一開始,我們先下載一個在ImageNet中已預先訓練過的CNN分類器。ImageNet是一個內含超過一百二十萬張被標記分類為1000種類別的高畫質圖片的資料庫。本範例將使用到AlexNet架構。

我們利用類神經網路工具箱(Neural Network Toolbox™)將AlexNet架構以SeriesNetwork匯入至MATLAB中,之後就會以CNN架構方式呈現。 這個SeriesNetwork 物件指令即代表了這個CNN。

我們已經把圖片分別儲存到位於母資料夾pet_images底下的cat 與dog 資料夾。使用這種資料夾結構的優點是,我們在MATLAB中建立的 imageDatastore之後能夠自動地讀取與管理圖片位置和分類標記。(imageDatastore是一個以MATLAB Datastore指令建立的資料庫,可分次有效率的處理檔案過大的資料以符合電腦記憶體容量) 然後,我們啟用imageDatastore,取得MATLAB裡的圖片。

接下來,我們選擇了一個具有相同數量的貓與狗圖片的資料子集。

由於AlexNet網路是在227x227-畫素(pixel)的圖片上進行訓練得到的,我們必須先把所有用來進行訓練的圖片調整成同樣的解析度,以下的程式碼讓我們可以同時從imageDatastore讀取及處理影像。

我們利用 readAndPreprocessImage函式將圖片解析度調整為227x227畫素。

執行特徵擷取 (Feature Extraction)
在這裡,我們打算使用預先訓練過的AlexNet CNN架構來處理新的資料集。CNN可以學習並擷取同屬性的特徵,可以被用來訓練出一個新的分類器以解決不同的問題,在本文範例指的是貓與狗的分類 (圖1)。

我們在CNN傳遞訓練的資料,並利用activations方法來擷取網路中特定層級(layer )的特徵。如同其他的類神經網路,CNN是由相互連結的非線性處理元件層級或是神經層所組成,輸入和輸出層與輸入和輸出訊號連結,而隱藏層級所提供的非線性錯縱性則給予類神經網路具備了運算能力。
當CNN的每一個層級對輸入的圖片產生回應時,只會有其中幾個層級適用於影像特徵的擷取,但沒有一個確定的公式可以確切地辨識出是哪些層級,最好的方式還是嘗試幾個不同的層級,並從它們的運作表現來觀察。
網路中最前面的幾個層級已經捕捉到基本的影像特徵,比如輪廓與區塊。為了更清楚地看到這些特徵,我們可以從第一個卷積層開始將網路過濾器的權重視覺化出來(圖2)。


要注意的是,網路的第一層已經學習了過濾器來捕捉區塊和輪廓的特徵。這些"基本”的特徵接著會由更深的網路層來處理,其中也結合了早期的特徵進而形成更高階的影像特徵。這些較高階的影像特徵更適合拿來進行辨識任務,因為所有的基本特徵都已被納入成為更豐富的影像表徵。你可以很容易地從一個較深的層級以activations方法來擷取特徵。
fc7分類層是一個很好的起始點。我們利用這個分類層來擷取訓練特徵。

利用擷取的特徵來訓練一個SVM分類器
現在我們已經可以利用從之前步驟擷取出來的特徵訓練一個”簡易”的分類器。要注意的是,我們最先套用的原始網路是被訓練來進行1000種物件類別的分類;而這個”簡易”的分類器只會被訓練來解決狗或貓的特定分類問題。
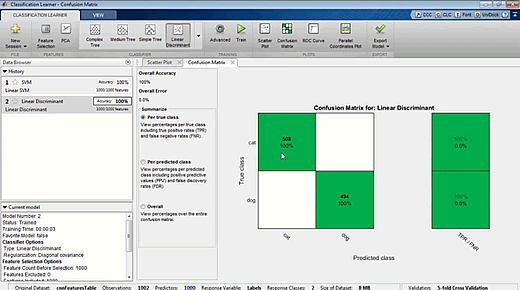
統計與機器學習工具箱(Statistics and Machine Learning Toolbox™)的分類學習應用程式(Classification Learner app)可以幫助我們訓練模型以及進行多個模型的相互比較(圖3)。
或者,我們也可以利用MATLAB語法來訓練分類器。
我們將資料分成兩組,其中一組用來訓練,另一組用來做測試。接下來,我們呼叫出 fitcsvm函式,以trainingFeatures作為輸入或預測子,並以trainingLabels作為輸出或回應值,來訓練一個支持向量機(support vector machine,SVM)分類器。我們以測試資料交叉驗證分類器來確認其驗證準確性,也就是對於分類器將如何處理新資料的無偏估計。

我們現在可以使用svmmdl分類器將圖片分類為貓或狗(圖4)。
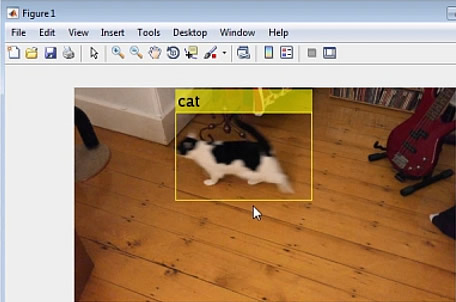
執行物件偵測
大多數的圖片或影像畫面都會有很多物件。舉例來說,除了狗之外可能還會有樹、一群鴿子、浣熊在追狗…等各式各樣的景物,即使是很可靠的影像分類器,也只是在我們已經可以確定想要分類的物件位置、把物件框出來、並將其餵進分類器時,也就是我們自己可以執行偵測物件的情況下可以表現得好。
針對偵測,我們使用的是一種稱作光流(optical flow)的技術,它利用了一段影片中一個一個畫面中畫素的動作。圖5為一段影片中的其中一個畫面,上面覆蓋了動作向量。

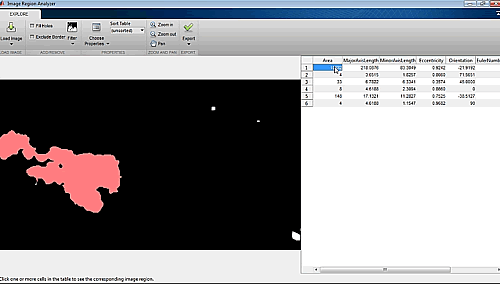
偵測處理的下一個步驟是要區分出移動中的畫素,並接著利用影像區域分析應用程式(Image Region Analyzer app)在二元影像中分析連接的組成,以過濾掉因為攝影機的移動而引起的雜訊。應用程式的輸出是一個MATLAB函式,可以確認寵物在視野中的位置(圖6)。
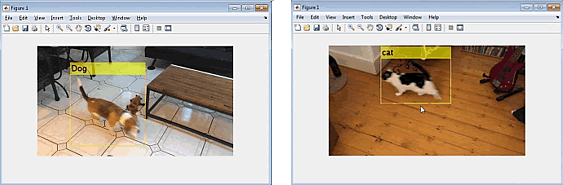
我們現在已經有了建立寵物偵測與辨識系統所需的元素(圖7)。這個系統可以:
- 在新的影像中利用光流技術偵測寵物位置。
- 從影像中框出寵物,並利用一個預先訓練的CNN來擷取特徵。
- 利用經過訓練的SVM分類器進行特徵分類,以決定圖片中的寵物屬於貓還是狗。
本篇文章中,我們利用現成的深度學習網路來解決一個困難的任務。現在,你也可以利用相同的技巧來解決你自己的影像分類問題--像是將影片中的車輛進行分類來分析交通流量、從質譜法資料辨識出腫瘤來進行癌症研究、或是依人類的臉部特徵來辨識身分的保全系統。